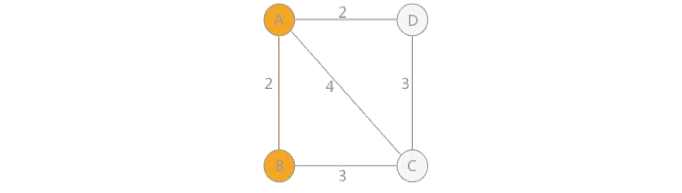
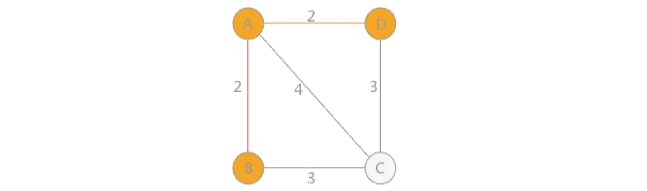
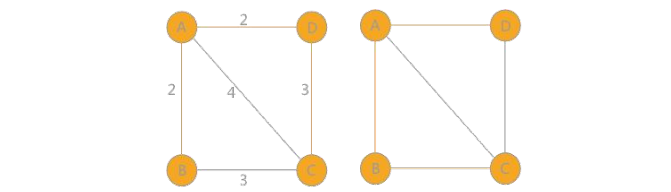
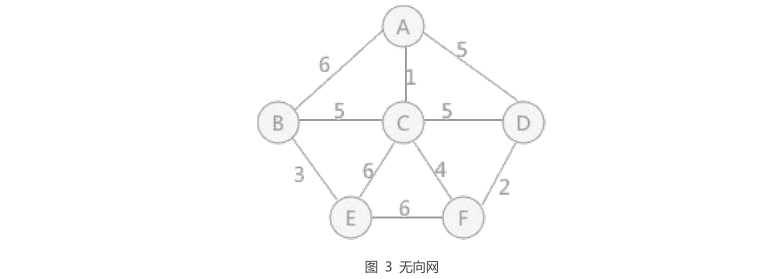
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
| #include <stdio.h>
#include <stdlib.h>
#define VertexType int
#define VRType int
#define MAX_VERtEX_NUM 20
#define InfoType char
#define INFINITY 65535
typedef struct {
VRType adj; //对于无权图,用 1 或 0 表示是否相邻;对于带权图,直接为权值。
InfoType * info; //弧额外含有的信息指针
}ArcCell,AdjMatrix[MAX_VERtEX_NUM][MAX_VERtEX_NUM];
typedef struct {
VertexType vexs[MAX_VERtEX_NUM]; //存储图中顶点数据
AdjMatrix arcs; //二维数组,记录顶点之间的关系
int vexnum,arcnum; //记录图的顶点数和弧(边)数
}MGraph;
//根据顶点本身数据,判断出顶点在二维数组中的位置
int LocateVex(MGraph G,VertexType v){
int i=0;
//遍历一维数组,找到变量v
for (; i<G.vexnum; i++) {
if (G.vexs[i]==v) {
return i;
}
}
return -1;
}
//构造无向网
void CreateUDN(MGraph* G){
scanf("%d,%d",&(G->vexnum),&(G->arcnum));
for (int i=0; i<G->vexnum; i++) {
scanf("%d",&(G->vexs[i]));
}
for (int i=0; i<G->vexnum; i++) {
for (int j=0; j<G->vexnum; j++) {
G->arcs[i][j].adj=INFINITY;
G->arcs[i][j].info=NULL;
}
}
for (int i=0; i<G->arcnum; i++) {
int v1,v2,w;
scanf("%d,%d,%d",&v1,&v2,&w);
int m=LocateVex(*G, v1);
int n=LocateVex(*G, v2);
if (m==-1 ||n==-1) {
printf("no this vertex\n");
return;
}
G->arcs[n][m].adj=w;
G->arcs[m][n].adj=w;
}
}
//辅助数组,用于每次筛选出权值最小的边的邻接点
typedef struct {
VertexType adjvex;//记录权值最小的边的起始点
VRType lowcost;//记录该边的权值
}closedge[MAX_VERtEX_NUM];
closedge theclose;//创建一个全局数组,因为每个函数中都会使用到
//在辅助数组中找出权值最小的边的数组下标,就可以间接找到此边的终点顶点。
int minimun(MGraph G,closedge close){
int min=INFINITY;
int min_i=-1;
for (int i=0; i<G.vexnum; i++) {
//权值为0,说明顶点已经归入最小生成树中;然后每次和min变量进行比较,最后找出最小的。
if (close[i].lowcost>0 && close[i].lowcost < min) {
min=close[i].lowcost;
min_i=i;
}
}
//返回最小权值所在的数组下标
return min_i;
}
//普里姆算法函数,G为无向网,u为在网中选择的任意顶点作为起始点
void miniSpanTreePrim(MGraph G,VertexType u){
//找到该起始点在顶点数组中的位置下标
int k=LocateVex(G, u);
//首先将与该起始点相关的所有边的信息:边的起始点和权值,存入辅助数组中相应的位置,例如(1,2)边,adjvex为0,lowcost为6,存入theclose[1]中,辅助数组的下标表示该边的顶点2
for (int i=0; i<G.vexnum; i++) {
if (i !=k) {
theclose[i].adjvex=k;
theclose[i].lowcost=G.arcs[k][i].adj;
}
}
//由于起始点已经归为最小生成树,所以辅助数组对应位置的权值为0,这样,遍历时就不会被选中
theclose[k].lowcost=0;
//选择下一个点,并更新辅助数组中的信息
for (int i=1; i<G.vexnum; i++) {
//找出权值最小的边所在数组下标
k=minimun(G, theclose);
//输出选择的路径
printf("v%d v%d\n",G.vexs[theclose[k].adjvex],G.vexs[k]);
//归入最小生成树的顶点的辅助数组中的权值设为0
theclose[k].lowcost=0;
//信息辅助数组中存储的信息,由于此时树中新加入了一个顶点,需要判断,由此顶点出发,到达其它各顶点的权值是否比之前记录的权值还要小,如果还小,则更新
for (int j=0; j<G.vexnum; j++) {
if (G.arcs[k][j].adj<theclose[j].lowcost) {
theclose[j].adjvex=k;
theclose[j].lowcost=G.arcs[k][j].adj;
}
}
}
printf("\n");
}
int main(){
MGraph G;
CreateUDN(&G);
miniSpanTreePrim(G, 1);
}
|