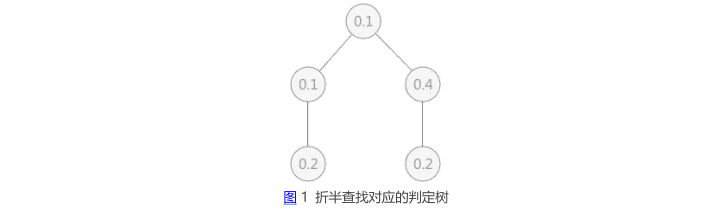
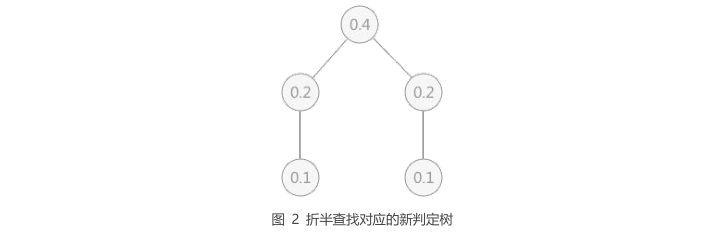
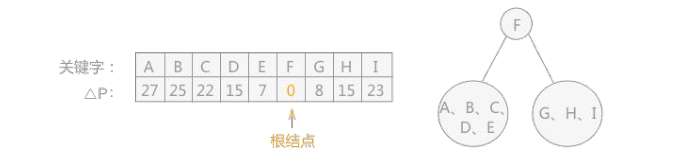
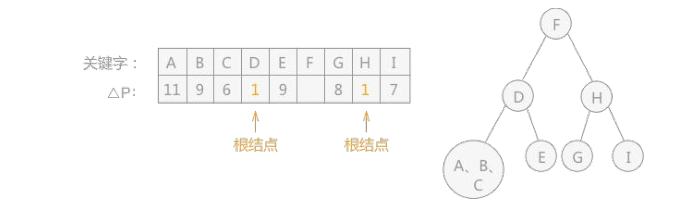
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| typedef int KeyType;//定义关键字类型
typedef struct {
KeyType key;
} ElemType; //定义元素类型
typedef struct BiTNode {
ElemType data;
struct BiTNode *lchild, *rchild;
} BiTNode, *BiTree;
//定义变量
int i;
int min;
int dw;
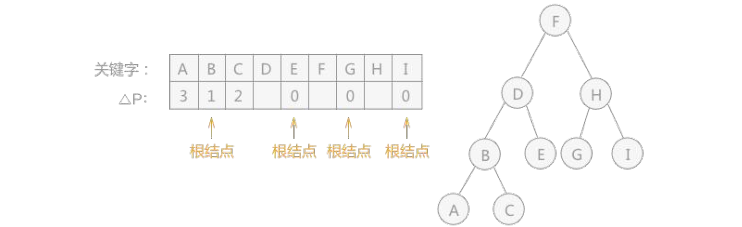
//创建次优查找树,R 数组为查找表,sw 数组为存储的各关键字的概率(权值),low 和 high 表示的 sw 数组中的权值的范围
void SecondOptimal(BiTree T, ElemType R[], float sw[], int low, int high) {
//由有序表 R[low...high]及其累计权值表 sw(其中 sw[0]==0)递归构造次优查找树
i = low;
min = abs(sw[high] - sw[low]);
dw = sw[high] + sw[low - 1];
//选择最小的△Pi 值
for (int j = low+1; j <=high; j++) {
if (abs(dw-sw[j]-sw[j-1])<min) {
i = j;
min = abs(dw - sw[j] - sw[j - 1]);
}
}
T = (BiTree)malloc(sizeof(BiTNode));
T->data = R[i];//生成结点(第一次生成根)
if (i == low) T->lchild = NULL;//左子树空
else SecondOptimal(T->lchild, R, sw, low, i - 1);//构造左子树
if (i == high) T->rchild = NULL;//右子树空
else SecondOptimal(T->rchild, R, sw, i + 1, high);//构造右子树
}
|