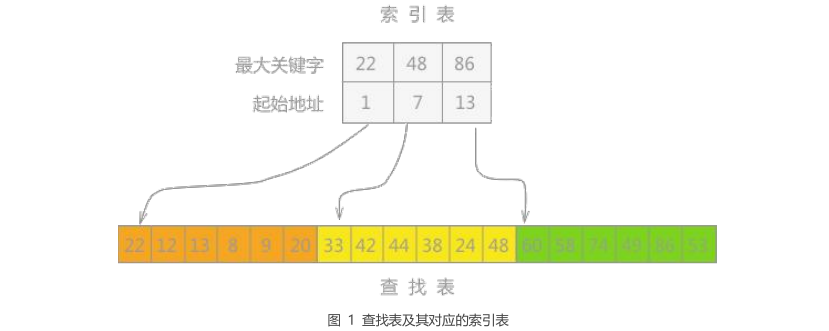
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| #include <stdio.h>
#include <stdlib.h>
struct index { //定义块的结构
int key;
int start;
} newIndex[3]; //定义结构体数组
int search(int key, int a[]);
int cmp(const void *a,const void* b){
return (*(struct index*)a).key>(*(struct index*)b).key?1:-1;
}
int main(){
int i, j=-1, k, key;
int a[] = {33,42,44,38,24,48, 22,12,13,8,9,20, 60,58,74,49,86,53};
//确认模块的起始值和最大值
for (i=0; i<3; i++) {
newIndex[i].start = j+1; //确定每个块范围的起始值
j += 6;
for (int k=newIndex[i].start; k<=j; k++) {
if (newIndex[i].key<a[k]) {
newIndex[i].key=a[k];
}
}
}
//对结构体按照 key 值进行排序
qsort(newIndex,3, sizeof(newIndex[0]), cmp);
//输入要查询的数,并调用函数进行查找
printf("请输入您想要查找的数:\n");
scanf("%d", &key);
k = search(key, a);
//输出查找的结果
if (k>0) {
printf("查找成功!您要找的数在数组中的位置是:%d\n",k+1);
}else{
printf("查找失败!您要找的数不在数组中。\n");
}
return 0;
}
int search(int key, int a[]){
int i, startValue;
i = 0;
while (i<3 && key>newIndex[i].key) { //确定在哪个块中,遍历每个块,确定key在哪个块中
i++;
}
if (i>=3) { //大于分得的块数,则返回0
return -1;
}
startValue = newIndex[i].start; //startValue等于块范围的起始值
while (startValue <= startValue+5 && a[startValue]!=key)
{
startValue++;
}
if (startValue>startValue+5) { //如果大于块范围的结束值,则说明没有要查找的数
return -1;
}
return startValue;
}
|