1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
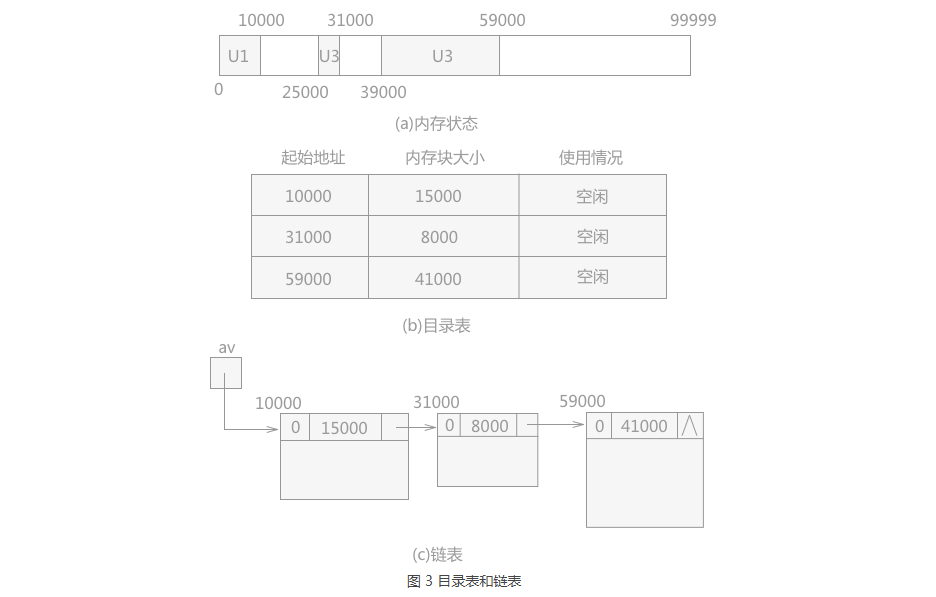
| 通常情况下系统中的可利用空间表是第 3 种情况。如图 3(C) 所示。
由于链表中各结点的大小不一,在用户申请内存空间时,就需要从可利用空间表中找出一个合适的结点,
有三种查找的方法:
1.首次拟合法:
在可利用空间表中从头开始依次遍历,将找到的第一个内存不小于用户申请空间的结点分配给用户,
剩余空间仍留在链表中;回收时只要将释放的空闲块插入在链表的表头即可。
2.最佳拟合法:
和首次拟合法不同,最佳拟合法是选择一块内存空间不小于用户申请空间,但是却最接近的一个结点分配给用户。
为了实现这个方法,首先要将链表中的各个结点按照存储空间的大小进行从小到大排序,
由此,在遍历的过程中只需要找到第一块大于用户申请空间的结点即可进行分配;
用户运行完成后,需要将空闲块根据其自身的大小插入到链表的相应位置。
3.最差拟合法:
和最佳拟合法正好相反,该方法是在不小于用户申请空间的所有结点中,
筛选出存储空间最大的结点,从该结点的内存空间中提取出相应的空间给用户使用。
为了实现这一方法,可以在开始前先将可利用空间表中的结点按照存储空间大小从大到小进行排序,
第一个结点自然就是最大的结点。
回收空间时,同样将释放的空闲块插入到相应的位置上。
|