JavaWeb开发思维导图之——Redis高级之主从复制常见问题(160)
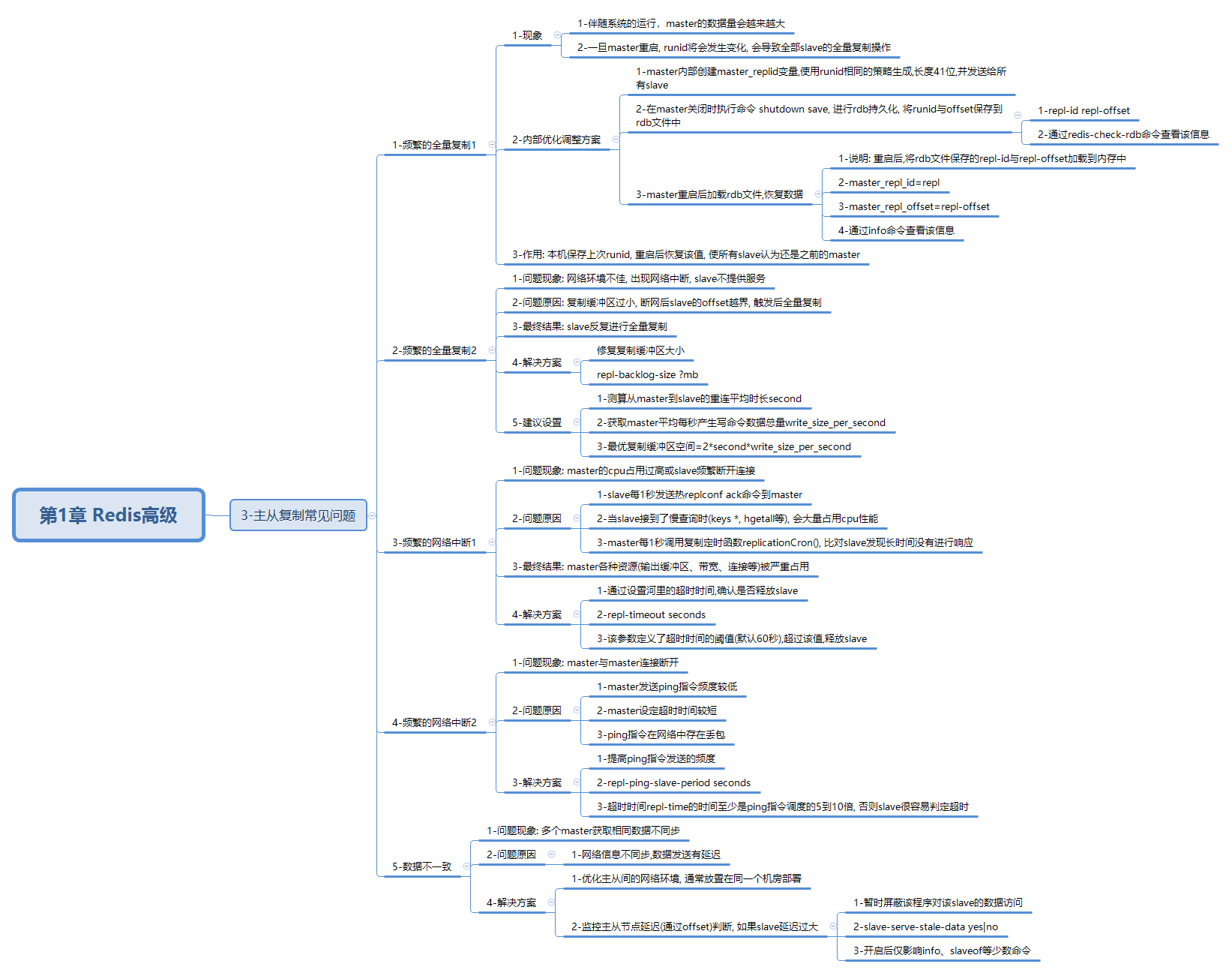
一 概述
- 频繁的全量复制1
- 频繁的全量复制2
- 频繁的网络中断1
- 频繁的网络中断2
- 数据不一致
二 频繁的全量复制1
2.1 现象
1 | 1-伴随系统的运行,master的数据量会越来越大 |
2.2 内部优化调整方案
1 | 1-master内部创建master_replid变量,使用runid相同的策略生成,长度41位,并发送给所有slave |
2.3 作用
1 | 本机保存上次runid, 重启后恢复该值, 使所有slave认为还是之前的master |
三 频繁的全量复制2
1 | 1-问题现象: 网络环境不佳, 出现网络中断, slave不提供服务 |
四 频繁的网络中断1
1 | 1-问题现象: master的cpu占用过高或slave频繁断开连接 |
五 频繁的网络中断2
5.1 问题现象:
1 | master与master连接断开 |
5.2 问题原因
1 | 1-master发送ping指令频度较低 |
5.3 解决方案
1 | 1-提高ping指令发送的频度 |
六 数据不一致
1 | 1-问题现象: 多个master获取相同数据不同步 |
七 思维导图