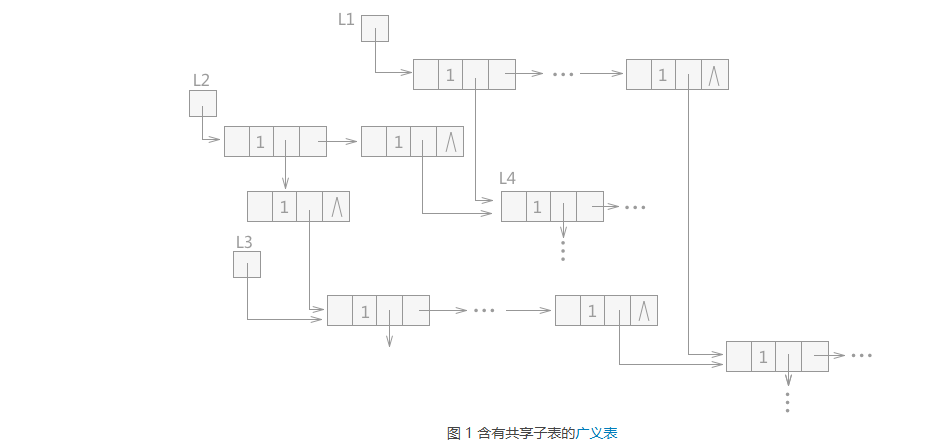
递归和非递归方式在前面章节做过详细介绍,第三种实现方式中代替栈的方法是: 添加三个指针,p 指针指向当前遍历的结点,t 指针永远指向 p 的父结点,q 指向 p 结点的表头或者表尾结点。 在遍历过程遵循以下原则:
一、当 q 指针指向 p 的表头结点时,可能出现 3 种情况
1 2 3 4 5
1.p 结点的表头结点只是一个元素结点,没有表头或者表尾,这时只需要对该表头结点打上标记后即 q 指向 p 的表尾; 2.p 结点的表头结点是空表或者是已经做过标记的子表,这时直接令 q 指针指向 p 结点的表尾即可; 3.p 结点的表头是未添加标记的子表,这时就需要遍历子表,令 p 指向 q,q 指向 q 的表头结点。 同时 t 指针相应地往下移动,但是在移动之前需要记录 t 指针的移动轨迹。 记录的方法就是令 p 结点的 hp 域指向 t,同时设置 tag 值为 0。
二、当 q 指针指向 p 的表尾结点时,可能出现 2 种情况:
1 2 3
1.p 指针的表尾是未加标记的子表,就需要遍历该子表,和之前的类似,令 p 指针和 t 指针做相应的移动, 在移动之前记录 t 指针的移动路径,方法是:用 p 结点的 tp 域指向 t 结点,然后在 t 指向 p,p 指向 q。 2.p 指针的表尾如果是空表或者已经做过标记的结点,这时 p 结点和 t 结点都回退到上一个位置。
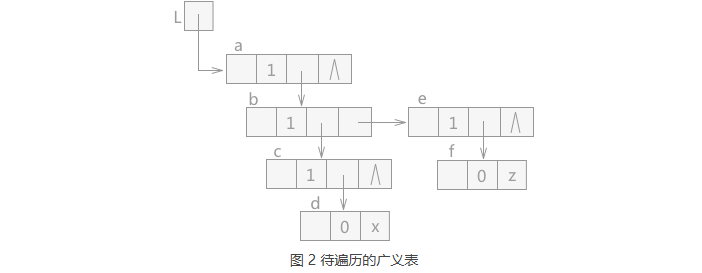
4.5 待遍历广义表
1 2
由于 t 结点的回退路径分别记录在结点的 hp 域或者 tp 域中,在回退时需要根据 tag 的值来判断: 如果 tag 值为 0 ,t 结点通过指向自身 hp 域的结点进行回退;反之,t 结点通过指向其 tp 域的结点进行回退。
4.6 几种情况
一、情况1
1
例如,图 2 中为一个待遍历的广义表,其中每个结点的结构如图 3 所示:
二、情况2
1 2
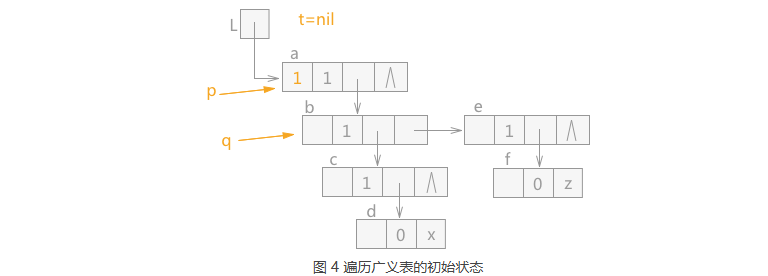
在遍历如图 2 中的广义表时,从广义表的 a 结点开始,则 p 指针指向结点 a,同时 a 结点中 mark 域设置为 1, 表示已经遍历过,t 指针为 nil,q 指针指向 a 结点的表头结点,初始状态如图 4 所示
三、情况3
1 2 3
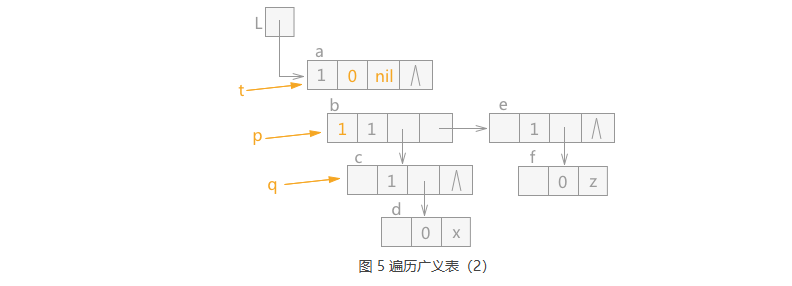
由于 q 指针指向的结点 b 的 tag 值为 1,表示该结点为表结构,所以此时 p 指向 q,q 指向结点 c, 同时 t 指针下移,在 t 指针指向结点 a 之前,a 结点中的 hp 域指向 t,同时 a 结点中 tag 值设为 0。 效果如图 5 所示:
四、情况4
1 2 3
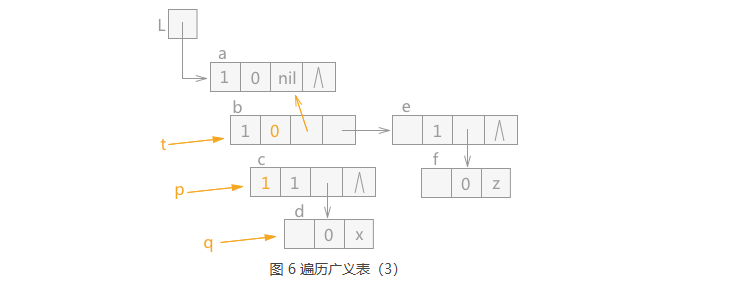
通过 q 指针指向的结点 c 的 tag=1,判断该结点为表结点,同样 p 指针指向 c,q 指针指向 d, 同时 t 指针继续下移,在 t 指针指向 结点 b 之前,b 结点的 tag 值更改为 0,同时 hp 域指向结点 a, 效果图如图 6 所示:
五、情况5
1 2 3
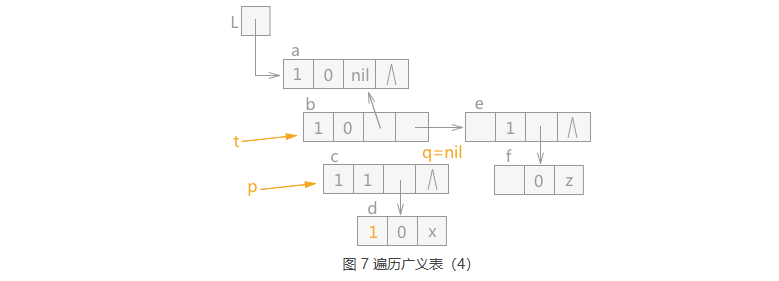
通过 q 指针指向的结点 d 的 tag=0,所以,该结点为原子结点,此时根据遵循的原则, 只需要将 q 指针指向的结点 d 的 mark 域标记为 1,然后让 q 指针直接指向 p 指针指向结点的表尾结点, 效果图如图 7 所示:
六、情况6
1 2 3 4 5
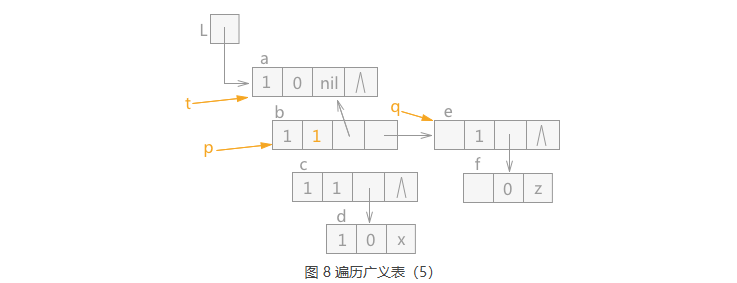
当 q 指针指向 p 指针的表尾结点时,同时 q 指针为空,这种情况的下一步操作为 p 指针和 t 指针全部上移动, 即 p 指针指向结点 b,同时 t 指针根据 b 结点的 hp 域回退到结点 a。 同时由于结点 b 的tag 值为 0,证明之前遍历的是表头,所以还需要遍历 b 结点的表尾结点, 同时将结点 b 的 tag 值改为 1。 效果图如图 8 所示:
七、情况7
1 2 3
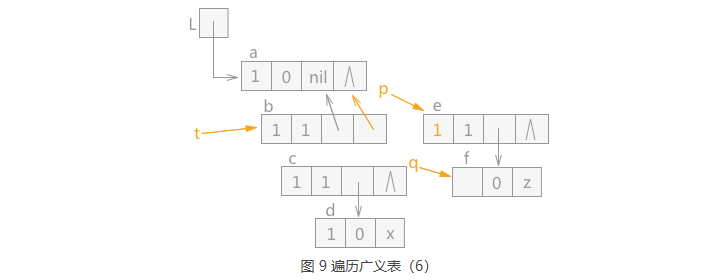
由于 q 指针指向的 e 结点为表结点,根据 q 指针指向的 e 结点是 p 指针指向的 b 结点的表尾结点, 所以所做的操作为:p 指针和 t 指针在下移之前,令 p 指针指向的结点 b 的 tp 域指向结点 a, 然后给 t 赋值 p,p 赋值 q。q 指向 q 的表头结点 f。效果如图 9 所示:
八、情况8
1 2
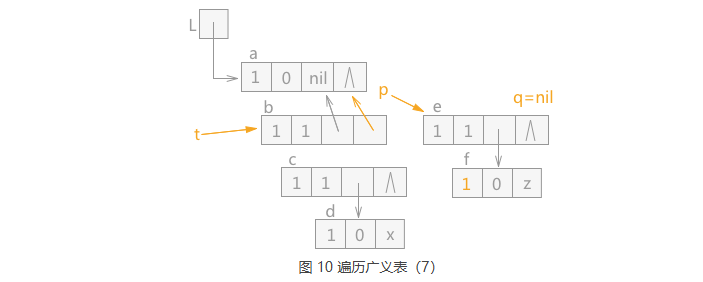
由于 q 指针指向的结点 f 为原子结点,所以直接 q 指针的 mark 域设为 1 后, 直接令 q 指针指向 p 指针指向的 e 结点的表尾结点。效果如图 10 所示:
1 2
由于 p 指针指向的 e 结点的表尾结点为空,所以 p 指针和 t 指针都回退。 由于 p 指针指向的结点 b 的 tag 值为 1,表明表尾已经遍历完成,所以 t 指针和 p 指针继续上移,最终遍历完成。